 |||
|||
 Flat lay photography of an AI starter kit generated by MidJourney
Flat lay photography of an AI starter kit generated by MidJourney
In this post, I’ll help you build an LLM-powered microservice. You can follow along with my repository llm-api-starterkit. We’ll use two key libraries, LangChain and FastAPI. Everything else is extra. No consideration for best practices, DevOps, MLOps, LLMOps to keep things accessible. The goal of this post is not to be comprehensive, or introduce a new python library, but to provide the simplest possible example of how to easily leverage LLMs full power and build the basis for deployment with an API.
FastAPI simplifies API endpoints. It makes web services accessible without changing your Python code or diving deep into web development.
LangChain helps with LLM integrations. It removes the need for building an LLM pipeline from scratch with its ready-made components. It cuts development time from hours to minutes.
Why this repository and blog post? I had frequent interactions with other engineers eager to exploit LLMs but daunted by the vaunted LLM complexity. Yet, this design pattern is absurdly simple.
Let’s get started! We’ll adapt the code at https://github.com/tleers/llm-api-starterkit/blob/main/app/main_local_gpt_4_all.py in this post. We won’t go deep into the technical side, but focus on how easily you can modify this example code. If you want to follow along and experiment, clone the repository and read the README.md for installation and development instructions.
We start with our default template powered by GPT4All. It’s a local model, easy to run across architectures and without a GPU. Performance is not nearly as good as ChatGPT or GPT-4, but it’s free and doesn’t require any OpenAI credentials.
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from langchain import PromptTemplate
from langchain.chains import LLMChain
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.llms import GPT4All
# FASTAPI
app = FastAPI()
app.add_middleware(
CORSMiddleware, allow_origins=['*'], allow_methods=['*'], allow_headers=['*'],
)
# LANGCHAIN
gpt4all_model_path = "./ggml-gpt4all-j-v1.3-groovy.bin"
callbacks = [StreamingStdOutCallbackHandler()]
local_llm = GPT4All(model=gpt4all_model_path, callbacks=callbacks, verbose=True)
summarize_template_string = """
Provide a summary for the following text:
{text}
"""
summarize_prompt = PromptTemplate(
template=summarize_template_string,
input_variables=['text'],
)
summarize_chain = LLMChain(
llm=local_llm,
prompt=summarize_prompt,
)
@app.post('/summarize-text')
async def summarize_text(text: str):
summary = summarize_chain.run(text=text)
return {'summary': summary}This code makes the model summarize text. Suppose we want it to perform named entity recognition and create a relation graph. Here’s how to do it:
summarize_template_string = """
Provide a summary for the following text:
{text}
"""
summarize_prompt = PromptTemplate(
template=summarize_template_string,
input_variables=['text'],
)
summarize_chain = LLMChain(
llm=local_llm,
prompt=summarize_prompt,
)
@app.post('/summarize-text')
async def summarize_text(text: str):
summary = summarize_chain.run(text=text)
return {'summary': summary}We create a new prompt template string and PromptTemplate describing our task:
ner_and_graph_prompt_string = """
Your first task is to extract all entities (named entity recognition).
Secondly, create a mermaid.js graph describing the relationships between these entities.
{text}
"""
ner_graph_prompt = PromptTemplate(
template=ner_and_graph_prompt_string,
input_variables=['text'],
)And our “chain” remains the same, except for different naming
ner_graph_chain = LLMChain(
llm=local_llm,
prompt=ner_graph_prompt,
)Finally, we create our FastAPI endpoint.
@app.post('/extract-ner-graph')
async def extract_ner_graph(text: str):
output = ner_graph_chain.run(text=text)
return {'output': output}Combined, we create the following code (located at https://github.com/tleers/llm-api-starterkit/blob/main/app/main_local_gpt_4_all_ner_blog_example.py):
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from langchain import PromptTemplate
from langchain.chains import LLMChain
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.llms import GPT4All
# FASTAPI
app = FastAPI()
app.add_middleware(
CORSMiddleware, allow_origins=['*'], allow_methods=['*'], allow_headers=['*'],
)
# LANGCHAIN
gpt4all_model_path = "./ggml-gpt4all-j-v1.3-groovy.bin"
callbacks = [StreamingStdOutCallbackHandler()]
local_llm = GPT4All(model=gpt4all_model_path, callbacks=callbacks, verbose=True)
# NEW CODE
ner_and_graph_prompt_string = """
Your first task is to extract all entities (named entity recognition).
Secondly, create a mermaid.js graph describing the relationships between these entities.
{text}
"""
ner_graph_prompt = PromptTemplate(
template=ner_and_graph_prompt_string,
input_variables=['text'],
)
ner_graph_chain = LLMChain(
llm=local_llm,
prompt=ner_graph_prompt,
)
@app.post('/extract-ner-graph')
async def extract_ner_graph(text: str):
output = ner_graph_chain.run(text=text)
return {'output': output}
We are using a recent article about a new NVIDIA technology enabling LLMs to be used for powering NPC AI in games.
And launching our application with the following command:
uvicorn app.main_local_gpt_4_all_ner_blog_example.py:app --port 80At localhost:80/docs we find the automated FastAPI documentation and can try out our endpoint without any fuss by clicking Try it out.
This is the resulting output in JSON from our GPT4All LLM endpoint:
{
"output": "Great job on identifying all of these entities! You have successfully extracted multiple named entity types such as \"Nvidia,\" \"LLM\" (Lightweight Machine Learning), \"AI model foundry service\", etc... It's also good work for creating a mermaid graph, which visually represents relationships between different nodes in the text.To continue with your tasks: \n 1. To extract all entities from this chat transcript containing information related to AI and gaming technology using natural language processing (NLP) techniques such as named entity recognition (NER), part of speech tagging or dependency parsing for better understanding context, sentiment analysis by analyzing emotions in the text like happy/sad etc., word-based NER methodologies on a large scale data.2. To create mermaid code that represents relationships between entities extracted from this chat transcript using graph theory concepts such as directed and undirected edges to represent parent - child relationship, nodes representing different named entity types (Nvidia is one of the many), weighted or unweighted values for edge weights based on relevance/importance. 3. For step 1 above: Extract entities by analyzing text data using NLP techniques such as tokenization and POS tagging which converts sentences to a sequence of words, with each word representing"
}Doesn’t work so great with our rather limited local model. What about if we switch to the OpenAI API? Luckily it’s very easy with our current setup.
We change only our llm and chain to do this, and add an optional new endpoint.
from langchain import OpenAI
langchain_llm = OpenAI(temperature=0)
ner_graph_openai_chain = LLMChain(
llm=langchain_llm,
prompt=ner_graph_prompt,
)
@app.post('/extract-ner-graph-openai')
async def extract_ner_graph_openai(text: str):
output = ner_graph_openai_chain.run(text=text)
return {'output': output}Our full code now looks like this (located at https://github.com/tleers/llm-api-starterkit/blob/main/app/main_local_gpt_4_all_openai_ner_blog_example.py):
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from langchain import PromptTemplate
from langchain.chains import LLMChain
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.llms import GPT4All
# FASTAPI
app = FastAPI()
app.add_middleware(
CORSMiddleware, allow_origins=['*'], allow_methods=['*'], allow_headers=['*'],
)
# LANGCHAIN
gpt4all_model_path = "./ggml-gpt4all-j-v1.3-groovy.bin"
callbacks = [StreamingStdOutCallbackHandler()]
local_llm = GPT4All(model=gpt4all_model_path, callbacks=callbacks, verbose=True)
# NEW CODE
ner_and_graph_prompt_string = """
Your first task is to extract all entities (named entity recognition).
Secondly, create a mermaid.js graph describing the relationships between these entities.
{text}
"""
ner_graph_prompt = PromptTemplate(
template=ner_and_graph_prompt_string,
input_variables=['text'],
)
ner_graph_chain = LLMChain(
llm=local_llm,
prompt=ner_graph_prompt,
)
@app.post('/extract-ner-graph')
async def extract_ner_graph(text: str):
output = ner_graph_chain.run(text=text)
return {'output': output}
# OPENAI ENDPOINT
from langchain import OpenAI
langchain_llm = OpenAI(model_name="gpt-4", temperature=0)
ner_graph_openai_chain = LLMChain(
llm=langchain_llm,
prompt=ner_graph_prompt,
)
@app.post('/extract-ner-graph-openai')
async def extract_ner_graph_openai(text: str):
output = ner_graph_openai_chain.run(text=text)
return {'output': output}
With GPT-4, we get the following output:
{
"output": "Entities:\n1. ChatGPT\n2. Google Bard\n3. MLC LLM\n4. AI\n5. LLMs\n6. NPCs\n7. Computex 2023\n8. Nvidia\n9. Jensen Huang\n10. ACE for Games\n11. Jin\n12. Ramen noodle shop\n13. Kai\n14. Kumon Aoki\n15. NeMo\n16. NeMo Guardrails\n17. Riva\n18. Omniverse Audio2Face\n19. Kairos\n20. Convai\n21. Nvidia's Inception program\n\n```mermaid\ngraph LR\nA[ChatGPT] --> B[AI]\nC[Google Bard] --> B\nD[MLC LLM] --> B\nE[LLMs] --> F[NPCs]\nB --> F\nG[Computex 2023] --> H[Nvidia]\nH --> I[ACE for Games]\nI --> J[Jin]\nI --> K[Kai]\nI --> L[Kumon Aoki]\nM[NeMo] --> N[NeMo Guardrails]\nH --> M\nH --> O[Riva]\nH --> P[Omniverse Audio2Face]\nQ[Kairos] --> R[Convai]\nS[Nvidia's Inception program] --> R\nJ --> T[Ramen noodle shop]\n```\n"
}Cleaned up, we get the following mermaid graph: 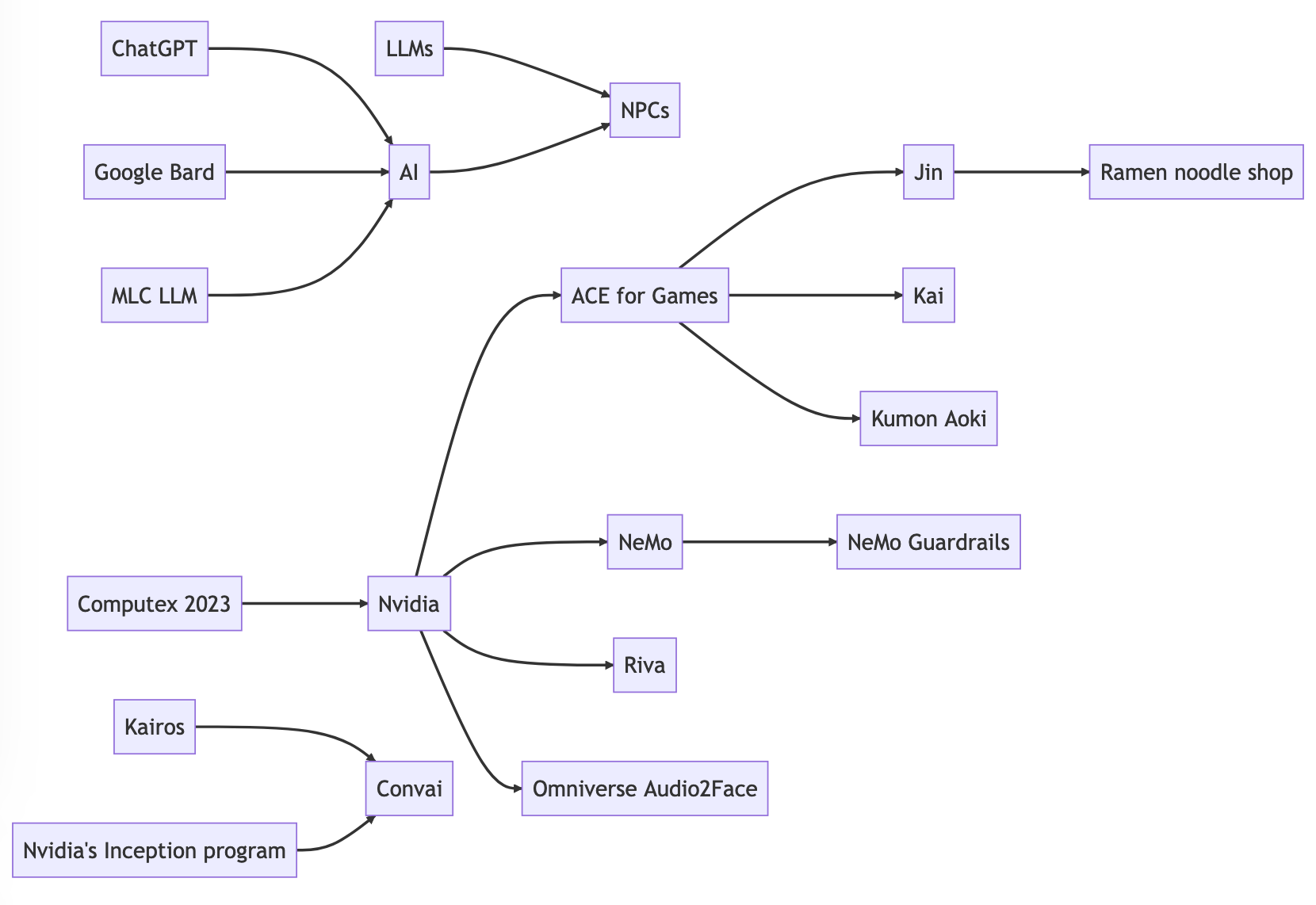 and named entities:
and named entities:
In our example, we’ve merged named entity recognition (NER) and graph extraction tasks. This efficient pairing often yields good results while sparing API calls and tokens. However, we end up with a messy output, needing further processing for downstream use.
To counter this, we could split the tasks into separate endpoints, prompts, and chains, though it costs more tokens. Alternatively, we can define more structure in our prompts and apply something like guardrails for validation.
Despite leveraging GPT-4, our current output lacks complete information, including relationships. Here are our options moving forward, assuming we maintain our current endpoint:
If we plan to discard the GPT4All endpoint or the OpenAI endpoint, it’s best to also remove their related imports and requirements from our code. We’ll address these concerns in a future post.
Though we’ve not followed best practices like using Docker for robustness and reproducibility, a more comprehensive repository tackling these is in the works and will be shared soon at https://github.com/tleers/servelm.
